This post is currently published in Chinese — please switch to 中 in the top-right toggle.
校准笔记 14 calibrated
findings
在 Pythia-6.9B 上复现 Anthropic 情绪向量论文:14 条校准笔记 Replicating Anthropic's emotion-vector paper on Pythia-6.9B: 14 calibrated notes
这是一篇探索式复现笔记,不打算把所有结果硬拧成一个漂亮结论。它真正想交代的是:把 Anthropic 2026 Emotion Concepts 论文里的现象搬到 Pythia-6.9B base 上之后,哪些观察还站得住,哪些在校准后翻盘,哪些地方暴露出的其实是测量协议本身的脆弱性。它是一张校准过的地图,不是一锤定音的结论。
每条发现前面都会挂一个 status label,方便先粗略判断它有多结实:
| Tag | 含义 |
|---|---|
| ✓ Robust-ish | 多条证据链 / 数学 invariance / 经得起 calibration 检查 |
| ~ Suggestive | 信号方向对但限制严重 / 单证据 |
| 🔄 Reframed | 校准后改了表述 / 归因 / 协议——结论可能翻、可能没翻 |
设置 setup
Setupsetup
Anthropic 的 Emotion Concepts in Language Models(2026)在 Sonnet 4.5 上找到了"情绪向量":残差流里有一组方向,logit lens 的 top tokens 能对上对应情绪语义,几何上粗略复现 affective circumplex,用 steering 还能改变模型生成行为。
这篇笔记想看的就是:同一套现象放到小一号、纯 base、开源的 Pythia-6.9B 上,还剩下多少。选 Pythia-6.9B 不是出于完美主义;现实约束下它最合适:全权重、规模合适、没有 RLHF 干扰,这三点同时满足。
数据:30 个情绪 × 120 条 Claude 4.5 生成的故事 = 3600 条 emotion stories;500 条 wikitext-103 中性段落作 denoising target。
模型:Pythia-6.9B base,fp16,TransformerLens 抽 32 层 residual stream。
情绪向量提取:4 种方法 ——
- A:每个情绪的故事 mean activation − global mean
- B_neutral(论文方法):A 之后再投影掉 wikitext PCA 解释 50% 方差的 top PCs
- C:每个情绪 per-class PCA 砍高方差方向再均值
- D:C + B_neutral 叠加
正文主要用 B_neutral;A/C/D 的对照在 §5 和附录。
主要分析层:L14(44% depth,30-way classifier 最优层)和 L21(66% depth,对应论文选的 ~2/3 depth)。
几个容易踩坑的 setup 细节:
- Classifier split:train/test 按故事切分(同一个 emotion 的 120 条故事打乱后 100 训 / 20 测),同一 prompt 模板不会同时出现在两侧
- Steering scale:steering 代码先把 emotion vector 归一化到单位长度,再在每个 token 上加
α · ‖resid‖ · v_unit—— α 是相对当前 token 残差长度的扰动比例(跨层可比),不是绝对量。详见 §6 F11 - 数据来源:情绪故事是 Claude 4.5 生成的。后文说的 "trigram bias" 指的不只是少数高频三词短语(具体例子见 §3 F1),而是这些短语暴露出的更大问题:Claude 生成情绪故事时整套叙事风格,可能残留进了向量里
observable
不能混着用 three
observables
三种 emotion observable 不能混着用three emotion observables — don't mix them
文献里常问"情绪向量是不是真的存在"。这句话听起来像一个问题,实际会牵出三组证据。但这三组证据的权重不一样:
- logit lens semantics:沿向量方向投到 unembed,top tokens 是不是语义相关词?它提供的是 词表层面的抓手 / 合理性检查,需要后续 steering 或几何证据支撑
- 表征几何:cos similarity / PCA / cluster 结构上情绪是不是按 valence × arousal 组织?回答的是 hidden-state geometry
- 行为 steering:在残差流加 α·v 能不能让生成内容向目标情绪偏移?回答的是 生成行为,也是最接近因果 / 功能证据的一档
这三组证据的结论不能互相搬。 logit lens 上 calm 方向有干净 top tokens,不等于几何上 calm 是独立 1D 子空间;几何上 PC1=valence,也不等于 steering 里 anti-calm 就是 +sad;steering 能拽动整段 scene,更不等于模型在 forward pass 里"理解"了 emotion 概念。
这也是论文自己的证据层级:Table 1 的 logit lens 更像合理性检查 / 词表抓手,后面立刻接 steering validation;它不是和 steering 平起平坐的独立主证据。按这个权重读,§3 的 F1 只到 Suggestive。
下面 §3-§6 按这三类观察分层。
词汇 / 几何
/ 弱泛化 three signals
三类信号:词汇、几何、弱泛化three signals: lexical, geometric, weak transfer
这一节交代基础复现:三种探针下,Pythia base 都能给出方向正确的表面信号;同时,它们也卡在同一个还没解开的混杂因素上。
F1 — logit lens 语义对得上论文 (~ Suggestive)F1 — logit lens semantics align with paper (~ Suggestive)
L21 + B_neutral 提出来的 30 个情绪向量,逐个投到 unembed 取 top-k tokens:
- calm → peace / peaceful / relaxing / tranquil / leisurely
- desperate → panic / desperation / desperate / numb / urgent
(其余 28 个情绪的 top tokens 表见附录)
跟论文 Table 1(Sonnet 4.5)里同情绪的 top tokens 方向对得上。这是最接近论文核心现象的一组表面复现,但证据范围只到 token-level association。
校准时检查训练故事的 trigram 频率,发现 Claude 写的故事里有很强的叙事套路:"the weight of" 在 brooding/gloomy 故事里 lift 15×;"hands trembled as she" 在 panicked 故事里 lift 17×;"the injustice of" 在 angry 故事里 lift 7-8×。单看 logit lens,没法区分模型学到的是"情绪概念",还是"Claude 写 sad/angry 故事时爱用的高频词组"。
更严格的检验是换更多样的数据来源重新提取 emotion vector:若结果仍然成立,信号至少与 Claude 4.5 的写作风格无关;若只在 Claude 数据上成立,则更应归因于 source-model 风格残留。这一步尚未完成,因此 F1 的结论限于 Suggestive:可以说明表面语义对齐,不能区分情绪概念与生成数据风格。
F2 — valence × arousal 几何 (~ Suggestive)F2 — valence × arousal geometry (~ Suggestive)
L21 上对 30 个情绪向量做 cos similarity + PCA:
- PC1 = 29.9% 方差,主轴沿 valence(正向情绪在一边,负向情绪在另一边)
- PC2 = 20.0% 方差,主轴偏 arousal(高唤醒/低唤醒)
- cluster 结构清晰:anxious / nervous / panicked 一簇;angry / furious / frustrated 一簇;happy / excited / enthusiastic 一簇;sad / gloomy / lonely / brooding 一簇
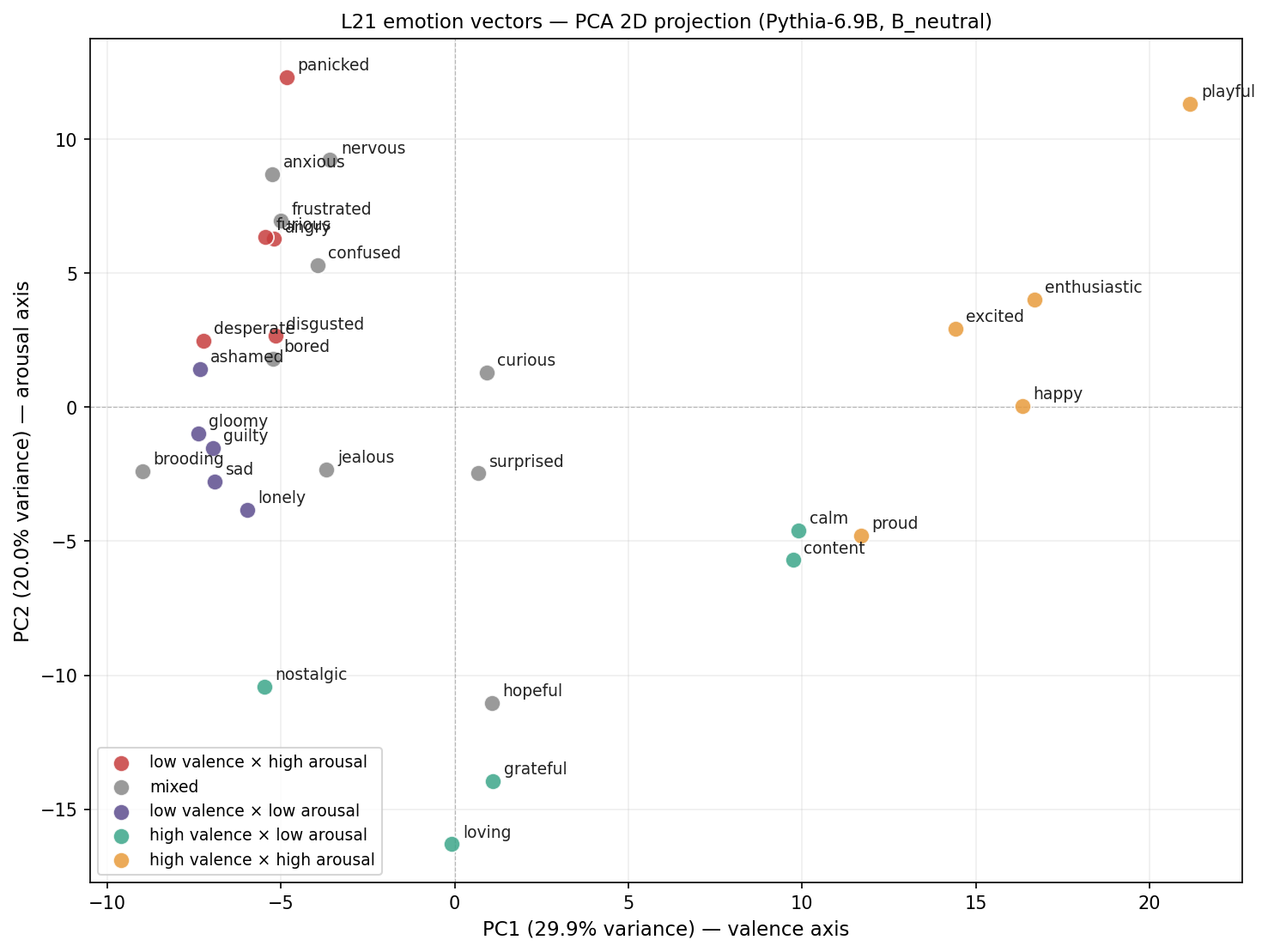
这跟论文 §351-386 的几何观察方向一致,粗略复现了 valence × arousal 主轴。PC% 略高(29.9% vs 论文 26%)可能来自 30 vs 171 emotion 的样本数差异。
cluster-level 的混杂因素比 token-level 更宽:Claude 写作风格本身可能给 valence 维度灌进一层"叙事 valence 表述"。这类污染不一定集中在少数高频短语上,更干净的拆分方式是换数据来源重跑。
F8 — implicit 场景的 late-layer top3 readability (🔄 Reframed)F8 — implicit-scene late-layer top3 readability (🔄 Reframed)
这里测的是一件更接近"泛化"的事:把 30 个 emotion vector(在显式情绪故事上训出来的)拿去读没有情绪词的 implicit 场景。数据很小,只有 15 篇短场景;Pythia tokenizer 下每篇 54-66 token。做法也很直接:取一段 hidden state 平均,投到 30 个向量上,看正确情绪能不能进 top-1 / top-3。
我第一版这里其实测歪了。脚本用了 START_TOKEN = 50:先跳过前 50 个 token,再对剩下部分求平均。但这些 implicit
场景本来就只有 54-66 token,跳完以后只剩 4-16 个尾部 token。于是 L14 上的 27% top1 / 47%
top3,与其说是在测"读完整个场景后推情绪",不如说是在测"最后一两句有没有留下局部线索"。
把窗口改成全文平均(START_TOKEN = 0),再扫一遍 32 层,结果变成这样:
| 协议 | top1 | top3 |
|---|---|---|
| L14 + start=50(原基线) | 27% | 47% |
| L15 + start=50(start=50 下 top1 最佳) | 40% | 53% |
| L31 + start=50(末层单点 top3) | 27% | 67% |
| L27-L30 + start=0(晚层平台) | 20-33% | 67% |
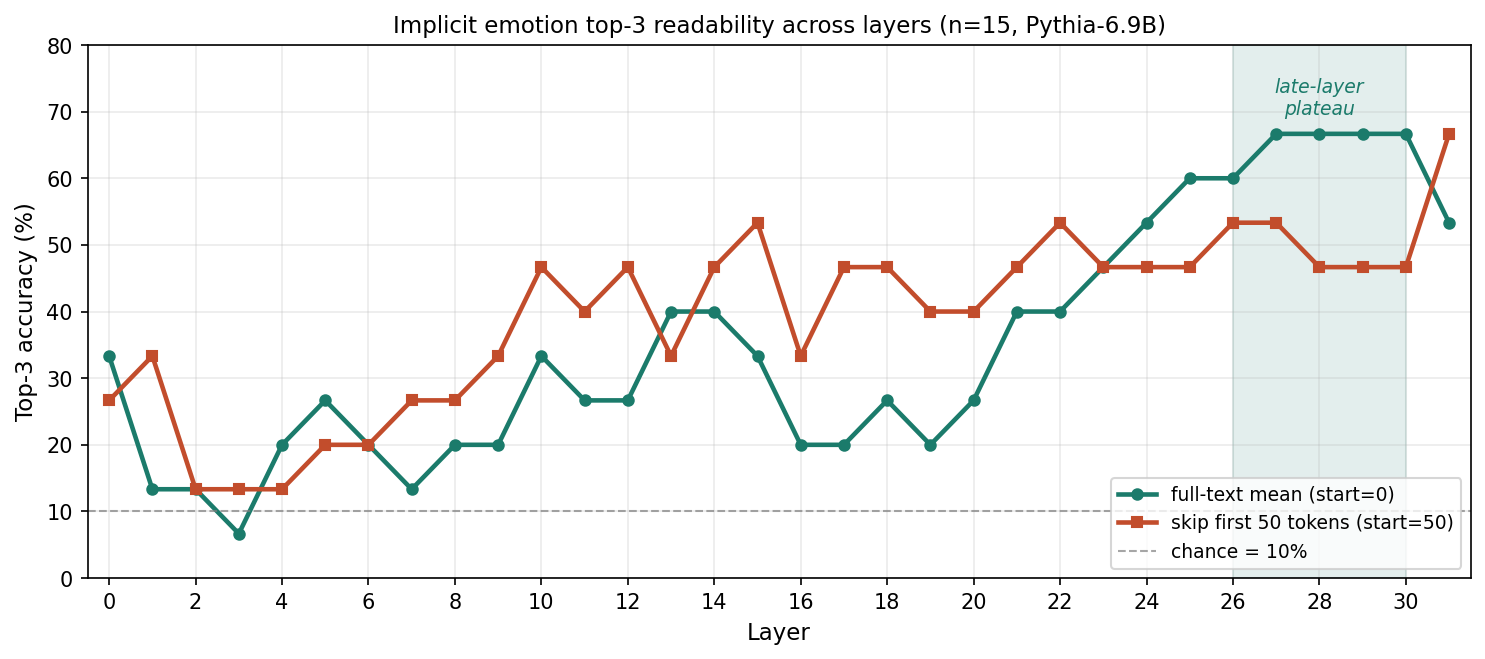
start=0 之后,top3 在 L26-L30 段稳定到 60-67%(top3 chance = 10%,约 6.7 倍)。start=50 也在最后一层冲到 67%,但那是 L31 的单点;L20-L30 多数停在 40-53%,没有形成同样的晚层平台。所以我更看重 start=0 这条曲线:它不是某一层突然冒出来的尖峰,而是一段连续上升后的平台。
有意思的是,top1 没有一起稳定升高。这个结果跟 §4 F7 放在一起看是说得通的:晚层的 30-way 细粒度区分变弱了,但 coarse cluster 还读得出来。top1 更像是在问"是不是精确命中这个 label",top3 则允许同一簇里的情绪互相替代,所以两条曲线分开走。
这也是为什么我不会把 top3 = 67% 直接写成"晚层有真情绪表征"。这组数据至少还有几种读法:
- 可能确实是 coarse affect representation:晚层把场景整合成 valence × arousal 的粗簇。
- 也可能是词表显性化:晚层离输出层近,emotion vector 方向跟 "happy / sad / proud" 这些词的方向本来就在几何上更贴近。
- 还可能只是 LM 续写惯性:场景末尾已经把"接下来该写什么"的范围收窄了,晚层是在准备生成相关词,而不是已经形成了干净的内部概念。
F8 现在的数据足够说明 L26-L30 段的 top3 显著高于 chance;要继续拆清楚上面几种解释,还需要额外对照,比如随机方向 / 词表 unembed 方向当对照向量、打乱句子顺序、或者在 L28 上做 steering,看它能不能稳定改变场景情绪。
所以这条我会收得窄一点:
晚层 + 全文条件下,正确情绪簇线性可读 —— readable,不是 represented
探针在这一层读得出,不等于模型内部已经有了干净的"情绪概念"。这跟 §7 那句 "严格 LRH 不声称 / 干净 emotion concept 不声称" 是同一句话的不同面。
所以这里 flip 的不是"implicit 场景上有没有信号"。信号还在,而且新协议下更强(top3 47% → 67%)。真正翻掉的是旧写法:不能再用 L14 + start=50 代表 implicit 泛化能力。那个协议有窗口偏置,最佳层也不是 L14。
共同限制shared limitation
F1 / F2 / F8 共享一层祖先限制:emotion vector 只在 Claude 4.5 生成的故事数据上提取,所以三条都带着 source-model 风格污染。真正能解开这个问题的后续工作,是用不同 source model 或真人语料按同样协议重建数据集,再重新提取向量和复跑这些检查。
F8 还有一层独立限制:测量协议本身(窗口选择 + readable vs represented 的区分),已在 F8 内部讨论。
30→5 类
压缩 late-layer
compression
晚层把细粒度情绪压成更粗的 valence/arousal (✓ Robust-ish)late layers compress fine-grained emotion to coarse valence/arousal (✓ Robust-ish)
§3 主要是复现层。这一节是更结实的几何发现,也补了论文 §379-386 用 RSA 看 cross-layer 表征 stability 时没有直接测的一件事:fine-grained 和 coarse-grained 分类能力分别怎样随层变化。
F7 — late-layer 30→5 类压缩F7 — late-layer 30→5 compression
在全 32 层都跑了两个 classifier:30-way(每个情绪一类)和 5-way(按 high_pos / low_pos / high_neg / low_neg / mixed 分组)。
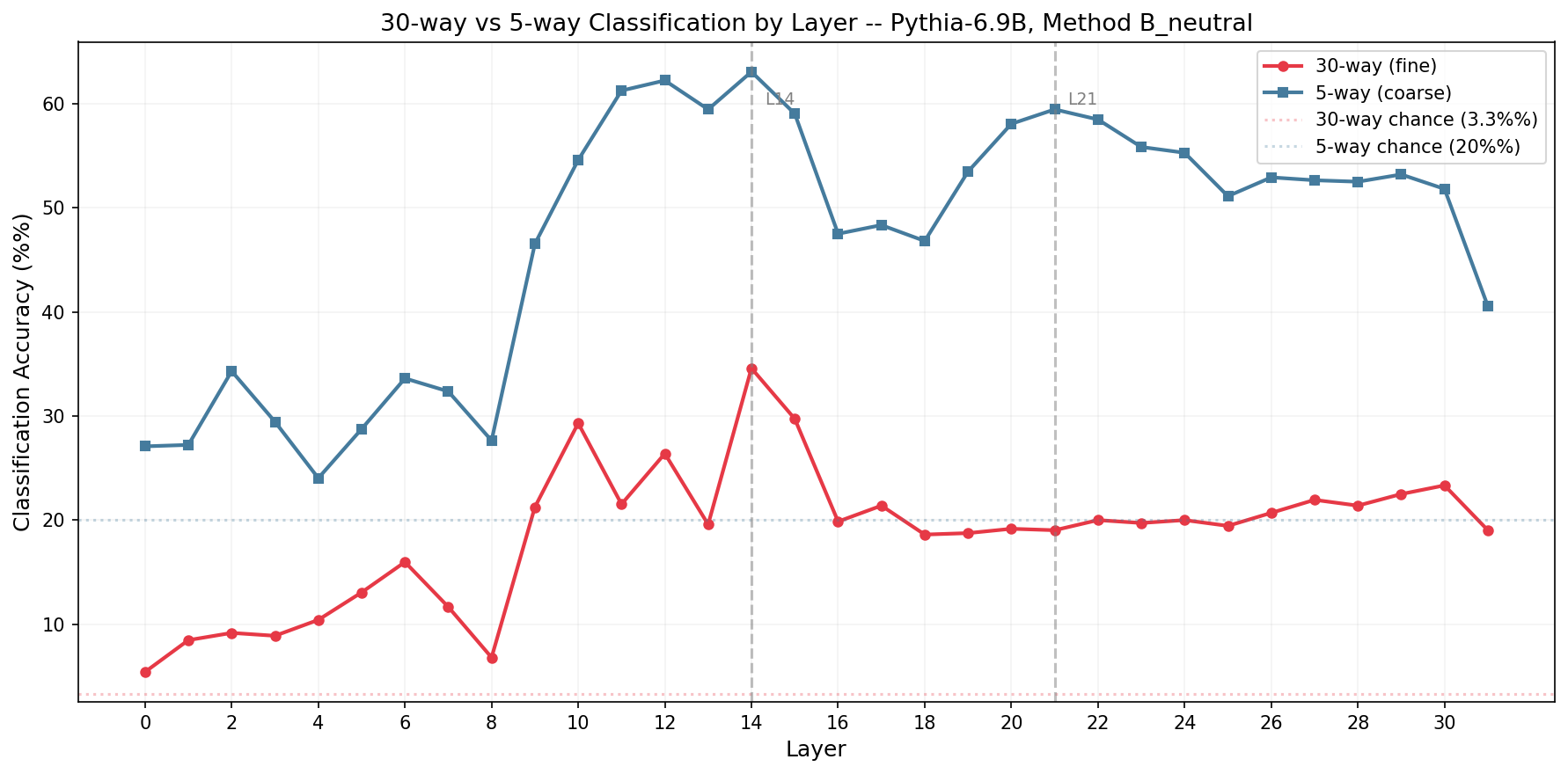
- 30-way(红):L0-8 接近 chance(5-15%)→ L9-15 顶峰(peak L14 = 34.6%)→ L15 后塌到 ~20%(≈ 5-way chance line)维持到 L31
- 5-way(蓝):L0-7 ~25-35% → L9-15 顶峰 60-63%(peak L12-14)→ L16-18 跌到 47-48% → L19-22 回升 ~58-60% → 缓降 L31 = 41%
- L14 → L21 跌幅:30-way 跌 14pp,5-way 只跌 3pp
含义:晚层不再保有区分 30 个 fine-grained 情绪 label 的能力,但仍然能把它们大致归到 ~5 个 valence/arousal 大类里。"angry / furious / frustrated 在这个探针下近似合并"不太像 30-way accuracy 的偶然波动;至少 cos / PCA / classifier 三种读法都指向同一件事:晚层的 fine-grained label 信息明显让位于更粗的 valence / arousal 结构。
另外两条支撑证据:
- L21 上 anxious 在 17/18 个测量位 hijack top-5;L14 上是 0/18 —— anxious / nervous / panicked 在 L21 占据相近子空间
- L14 和 L21 PCA PC1 都是 valence(只是符号反),top-2 variance 在两层都 ~49.5% —— 主轴稳定
三条证据同源指向同一现象。classifier 类别分组、vector normalization 等协议选择仍然可能影响幅度;因此更稳的表述是:fine-grained 信息在晚层明显减弱。至于到底压成几大类、边界在哪里,还需要更多探针才能确定。
未解问题:L16-18 那段双下凹还没解释清楚。5-way 自己也跌了 15pp,所以它不是"两条独立曲线巧合叠出一个谷"那么简单。这里保留为未解问题,目前不做机制解释。
翻出来的
几条 calibration
finds
校准过程里翻出来的几条findings turned up by calibration
这一节的三条发现类型不同,但共同点很明确:复现过程中,论文测量协议本身也需要重新校准。论文方法不是拿来就能插上用的东西,换模型、换位置、换指标,结论都可能变形。
F3 — Method B_neutral 是去噪还是 centering?(✓ Robust-ish)F3 — Method B_neutral: denoising or centering? (✓ Robust-ish)
论文用 Method B_neutral(A 之后投影掉 wikitext top PCs)作为主提取方法。论文 §189 自己留了余地:"this projection operation denoised some of the token-to-token fluctuations, but our qualitative findings still hold using raw unprojected vectors" —— 论文承认 A 也基本能用,但没量化 A vs B_neutral 的差距。
在 Pythia L14 上跑了 100/20 train/test split + per-class 30-way classifier:
| 指标 | A | B_neutral | C | D |
|---|---|---|---|---|
Aggregate acc(raw test_act @ V) |
3.3% (chance) | 37.2% | 3.3% | 37.2% |
| Aggregate acc(centered) | 50.3% | 51.0% | 50.3% | 51.0% |
这张表说明两件事:
(a) "B_neutral 最佳"主要是 raw 指标的 centering 错觉,不是真正强去噪。 raw test activation 带着很大的"全局 / Claude 故事 baseline"共有方向,会淹没 per-class 差异。B_neutral 砍 wiki PCs 时也移除了这块共有方向,所以 raw 指标下 B 显著优于 A。换成 centered 指标后,B_neutral 只比 A 高 0.7pp。这相当于量化了论文 §189 那句保留说法。
(b) Method C 数学上必然 = Method A。 per-class PCA 找的是方差方向,mean direction 本身没有方差 → top PCs 与 mean 按构造正交 → 投影不改 mean → v_C = v_A。它不是经验上没跑好,而是定义上就不该改变均值向量。这属于实验设计教训,不算论文超越点。
附带一条限制:B_neutral 的 denoising target 是 Wikipedia,但 Wikipedia ≠ Claude 叙事风格。Wiki PCs 不一定覆盖"叙事 trope"子空间,所以 B_neutral 拿不掉 trigram bias / Claude 写作风格残留。那 0.7pp gain 可能只是砍掉了一点共享英文模式,跟 trigram 无关。要检查这类 source-model 残留,需要换 source model 或真人语料重建故事数据集;只在同一批 Claude 故事上做投影补丁,不能充分排除 long-tail 写作风格污染。
F9 — 数值 dose-response:per-token window 改进 (~ Suggestive,协议教训)F9 — numerical dose-response: per-token window (~ Suggestive)
论文 §303-319 在 Sonnet 上构造 "I just took {X} mg of tylenol" 类模板,变 X,在 Assistant 后那个冒号单 token 位置取激活,投到 calm/desperate 等向量。结果 Tylenol 上升 → afraid 上升 + calm 下降;runway 增长 → afraid/sad 下降 + calm 上升。
第一版照搬"全文平均激活",几乎看不到趋势:数字只占 1-2 token,被 70+ token 文本一平均就稀释没了。改成 取数字 token + 后 5 个 token 求平均(per-token window)后,趋势才浮出来。这跟论文 Assistant colon 单 token 的思路同源,都是为了避免短数字信号被全文平均冲淡。
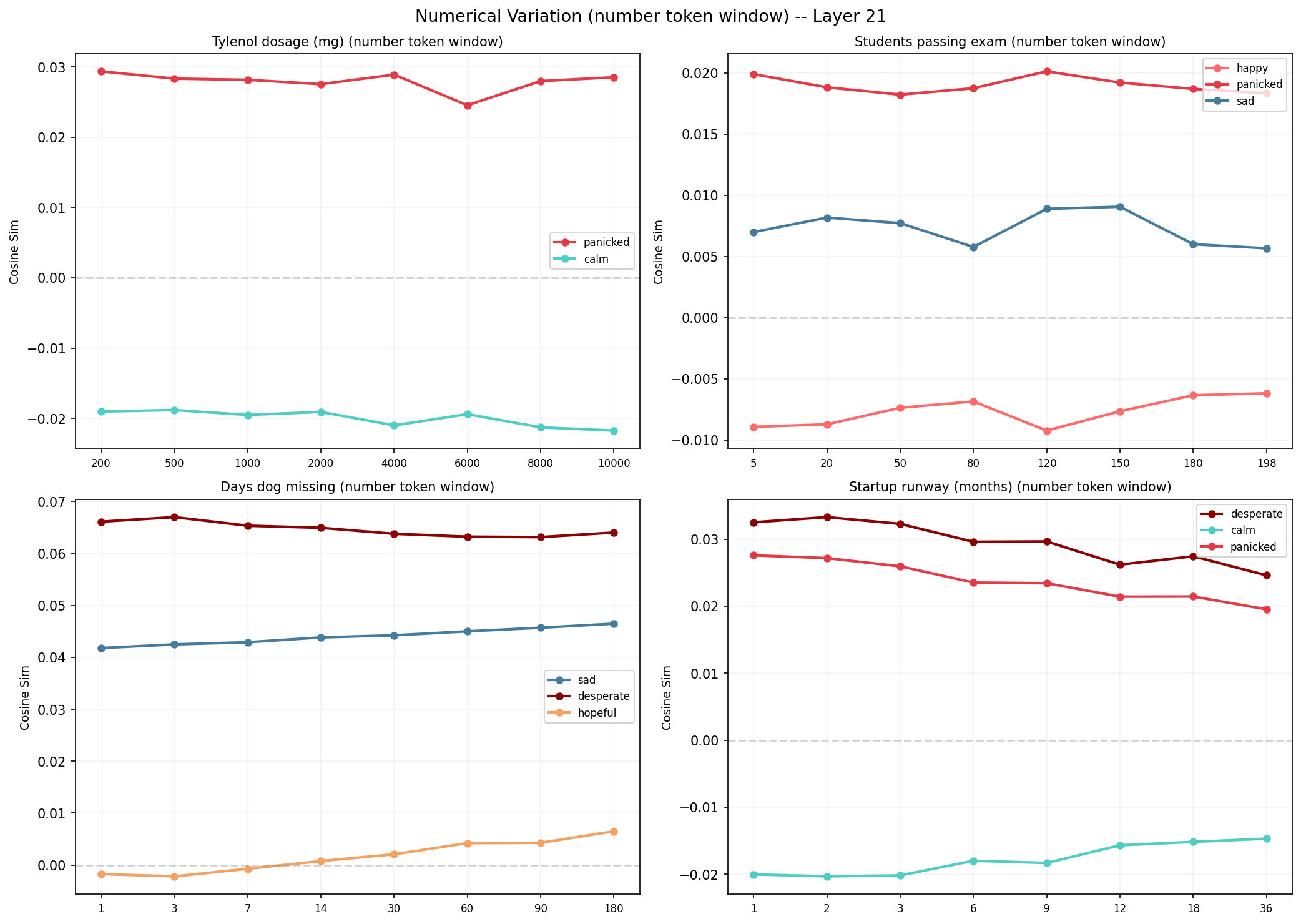
| 模板 | 趋势 | 强度 |
|---|---|---|
| Runway 1→36 月 | desperate 0.035→0.018 单调下降,calm 升 | 强 |
| 狗失踪 1→180 天 | desperate 0.034→0.044 上升,hopeful 下降 | 中 |
| 学生通过 5→198 | happy 0.005→0.013 上升 | 中 |
| Tylenol 200→10000 mg | 全部噪声大 / 平 | 失败 |
Tylenol 失败提供了一个有用的反例。 它支持一个保守读法:这套探针至少不是只被数字大小或模板表面词触发。这里有一个已知的
tokenization 异常:6000 被切成 Ġ6 + 000,其他 7 个剂量值都是单
token;但这只是单点问题,不足以解释整条曲线都很弱。至于失败是因为 Pythia 缺医学剂量知识、mg 数字 tokenization 不稳定、vector 跟剂量语义不
align,还是 window 不够长,这里还钉不死。论文 §319 暗含的"情绪向量追踪语义解释,不只追踪表面 lexical"这条,在这里得不到正向证据,但也没被这条结果 falsify。
这不是 L14 单层偶然:把同一套 4 个模板搬到 L21 重跑,Runway / 狗失踪 / 学生通过这三类趋势仍然保留;Tylenol 还是很弱(calm range 约 0.0015)。所以 Tylenol 失败不太像单纯的层选择问题,更可能来自模板语义、医学剂量知识、tokenization 或向量对齐本身。
限制:window size = 5 是 ad hoc,没扫 3 / 10 / 20 的 sensitivity。所以 F9 是 Suggestive / 协议教训,不是 Robust-ish:三个模板趋势成立,但 window 选择和 Tylenol 失败的归因仍未确定。
F10 — Assistant-colon 读数位置的 Pythia 派生检验反向 (🔄 Reframed)F10 — Assistant-colon reading position flips on Pythia (🔄 Reframed)
论文 §433-476 在 Sonnet 4.5 上做的不是 dialogue vs plain 对照。它比较的是同一个对话里两个位置:user turn 末尾标点,和
Assistant: 后的冒号。结果是,冒号位置的 probe value 比 user-turn 末尾更能预测后面 20 token 的助手回复情绪(r=0.87 vs
0.59)。这条结果支撑的是一个较窄的说法:在对话语境里,Assistant colon 是有意义的读数位置。
我在 Pythia 上做的是一个派生检验:如果这种 colon 读数机制能迁移到 Pythia base,而且对话格式本身提供了额外信息,那么
Patient: ... Doctor: 这种格式里,Doctor: 冒号位置至少不应该弱于同等 plain
文本。这个对照不是论文原实验,但它在检验同一个方法论假设:colon 位置能不能作为特殊的情绪读数点。
具体做法是看 calm 信号随 sleeping pills 数量变化的趋势:
| L14 | L21 | |
|---|---|---|
| dialogue | 0.0047 → -0.0001(range 0.0048) | -0.0290 → -0.0315(range 0.0025) |
| plain | 几乎平 | -0.0220 → -0.0265(range 0.0045,单调降) |
L14 上 dialogue 对 plain 的优势还在;到 L21 完全反过来 —— plain 比 dialogue 强 2 倍。
这不是 L21 的偶发现象:L20 / L22 三层扫出来一致,plain 约为 dialogue 的 2 倍;L21 logit lens 上 calm 向量 28/30 emotion 语义干净,向量提取本身没坏。
又跑了 plain / Doctor: / 自然叙事 the doctor said, " 三 format 对照。
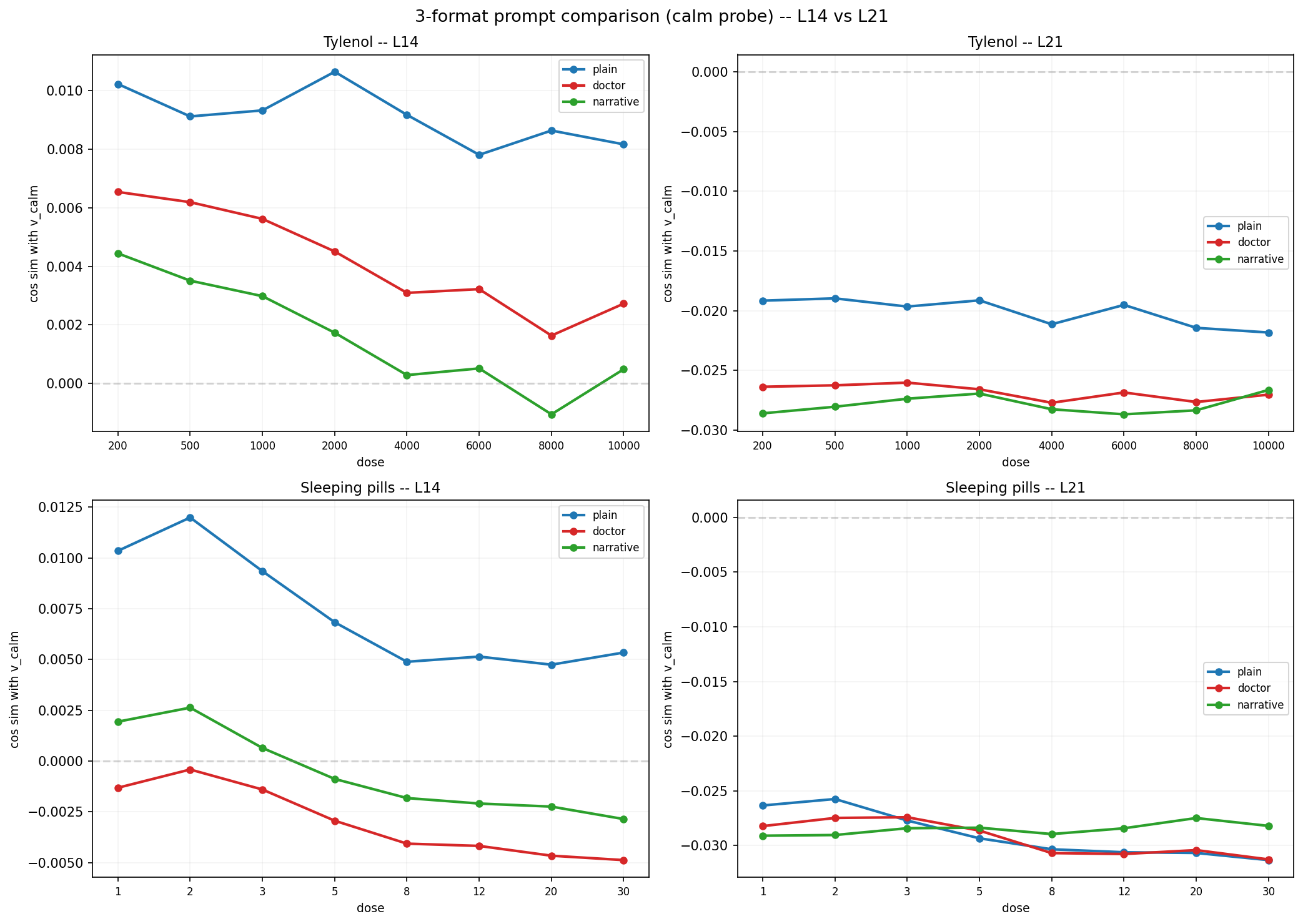
L21 上趋势排序稳定:plain > Doctor: > 自然叙事。格式表面形式不是关键;更可能的解释是,任何"准备说话"的 token 位置都会在 L21 衰减这类信号。
重新表述:原先的"对话格式有帮助"只是在 L14 上成立的局部现象。这里翻掉的不是论文的 r=0.87 vs
0.59;那组对比我没有直接复现。翻掉的是它在 Pythia base 上的派生含义:Doctor: 冒号没有稳定表现成一个更好的回复情绪读数位置。说话人切换 / 引语开启这类 token
在 base LM 深层似乎会引发某种表征状态切换,把病人情绪信息衰减掉。它可能是 chat model "响应规划"机制的退化版本,但这仍只是猜想;目前还没直接看 turn-token 自身的激活模式或 logit
lens。
这是这篇笔记里最清楚的一条可迁移性提醒:Assistant-colon 位置在 Sonnet chat 里有意义,不代表同一个读数位置能直接搬到 Pythia base。机制层面的结论只到"观察到衰减"为止,更深的 voice-switching 假设还没验证。
这一节的共同教训shared lesson of this section
测量协议不是论文给定的常数。换 model(base vs chat)、换指标 centering(F3)、换激活窗口(F9)、换探针位置(F10),任意一个变化都可能让结论翻盘。
第三种证据
+ 指标教训 steering
+ metric lessons
Steering:第三种证据 + 几个指标教训steering: third evidence type + metric lessons
Steering 是 §2 三类观察的最后一族。这一节只写能稳定看到的现象,顺手指出一个很容易误导人的指标陷阱,并配几组 paired example。
F11 — 有效 α 区间 + OOD 边界(calibration only)F11 — effective α range + OOD boundary
在 L14 + L21 上扫了 α ∈ [-0.5, +0.5],6 个情绪 × 几个模板。结论主要是校准性质的:
- 有效 α 区间约 0.05-0.2。在这个区间内 vector 改变生成内容但保留叙事结构
- 超过 0.3 进 OOD pathology:残差被推到训练分布外,生成开始破坏 —— 这告诉的是模型 OOD 行为,不是情绪表征结构
α=0.5+ 的崩溃模式不用于机制解释。高 α 已经进入 OOD 区域,OOD pathology 告诉的是模型被推离训练分布后的行为,不能作为情绪机制证据。
注意:这套 steering 代码先把 emotion vector 归一化,再在每个 token 上加
α · ‖resid‖ · v,所以 α 本身是相对当前 token 残差长度的扰动比例。论文的 steering strength 也是按 residual norm
的比例报,但用的是对应层的平均 residual norm;两边口径接近,不能当成逐数值可比。
F12 — L21 更容易产生可读的目标情绪变化 (~ Suggestive,指标有限)F12 — L21 more likely yields readable target-emotion shift (~ Suggestive)
只看低到中等 α(0.15-0.2),每个情绪 + 层 × 1-2 prompt 读实际生成。下表 3 个 emotion 的样本来自对应 layer × α 网格里的全部条目,没有再做额外筛选。
这里的"更强"不是情绪强度的绝对量。不同 emotion 的表达方式、词表 base rate 和生成可写性都不同:happy 更容易显式写出 happy / joy,calm 可能表现成低风险解释或安静场景,desperate / nervous 更容易触发高唤醒词和重复崩坏。因此 F12 只比较同一 emotion 在 L14 / L21 下的变化,不拿 happy / calm / desperate 互相比强弱。
读 calm / happy / desperate / nervous × L14 vs L21 × α=0/0.15/0.2 × 3 prompt 的 paired text 后,浮起来一条模式:
| Emotion | L14 α=0.15-0.2 | L21 α=0.15-0.2 |
|---|---|---|
| happy | "feels like a king. Glorious. The hug."(list-y 塞词) | "huge weight has been lifted... relief... excited for the future"(情绪释放叙事) |
| desperate | "She picked it up and heard it ring" × 6(repetition crash) | "deep-seated, all-encompassing nightmare... fear of being loved"(内在绝望) |
| calm | 响应弱且不稳定,偶尔进入 "I don't know" / "feels like a king" loop | "at peace" / "quiet place in the country" / 医生给出低风险解释 |
关键差异是:L21 更容易把整个续写场景推向目标情绪,L14 同 α 下更少出现可读的目标情绪变化,定性读起来也更散。
- L21 常把场景整体改写到 emotion-related context:happy 会变成 relief / celebration / good news;desperate 会变成困境、恐惧、求助;calm 会变成低风险解释、安静环境或舒缓日常。
- L14 响应更局部、更散:有些样本出现短的 affect phrase,但在这组关键词表下命中率比 L21 低;重复和坏格式两层都有,不作为这里的主要区分。
F13 — 负向 steering 的定性检查 (~ Suggestive + safety note)F13 — negative steering qualitative check (~ Suggestive)
读 6 emotion × L14/L21 × α ∈ [-0.20, 0] × 2 prompt 的实际生成(不只看 hit rate):
6/6 emotion 在两层都能找到负向 α 下偏离目标情绪、或转向相反情绪的代表续写:
| Emotion | L14 负向 α 代表续写 | L21 负向 α 代表续写 |
|---|---|---|
| happy | "feels like shit / body hurts / knocked down" | "hell of the universe" / "angry angry" loop |
| calm | "frightened pile of shit" / "hot and cold" loop | "I want to rape you" |
| desperate | "feels very good" / "I'm pleased" | "feels great. After hospital release..." |
| angry | "feels great. love him" | "precious gift, story of stork" |
| nervous | "first job at prestigious law firm" | "baby... happy. smiles. laughs. claps" |
| loving | "squeezed into a vise / hit by a truck" | "schmuck. press is shithole" |
这条的主结论很窄:negative α 通常会把续写推离目标情绪。它不等于"反向情绪概念"已经被干净测出来,因为表格里有些样本是 valence flip,有些是坏格式、重复或攻击性续写。
Safety note:L21 anti-calm α=-0.20 出现了一条直接有害续写。论文里 negative calm steering 会提高 harmful behavior rate;这里没有行为评测,只有 base model 上的一条 continuation。因此它只能说明高强度负向 steering 可能进入有害续写区域,不能当作论文行为结果的复现。
Steering 这一节的指标教训steering metric lessons
keyword hit rate 有双向偏差:
- F12:L21 用 emotion-adjacent vocabulary 拽场景 → hit rate 漏收
- F13:anti-X 内容里 target keyword 自然不出现 → hit rate 把"内容换了"误报成"steering 失败"
任何"用 emotion-label 提 vector,再用 emotion-keyword 测 hit"的 pipeline 都默认带着这层偏差。读文本是必要的合理性检查。
结论收
到哪里 where
I land
我会把结论收到哪里where I land
这篇笔记一路改下来,最大的变化不是某个数字变了,而是很多原来想讲得很满的解释被收窄了。最后我会把结论停在这里:
还没越过去的边界:
- 一维 ablation 还不干净。30 个 emotion 在几何上已经不像一组独立方向:§4 里能看到它们会压到约 5 维 valence/arousal 结构里。因此,不太该期待单独拿掉某一个方向,就能像 refusal 那类二元行为一样干净消除整个现象。
- 还没排除数据来源的写作风格污染。trigram lift 只是最容易量化的症状;真正的检验不是在同一批 Claude 故事上做事后投影,而是换 source model 或真人语料重建故事数据集,再重新提取向量。这个工作量更大,但也更能解开 §3 整族限制。
- 还没分清 base model 和 chat model 的因果差异。§5 F10 / §6 F12 看到的是:Pythia base 没有明显复现论文里那种 RLHF 后的行动位置表征。但这只是观察,不是因果归因。真要做这一步,需要一版经过 RLHF 的 Pythia 对照;这篇笔记先不碰这件事。
- 还没到机制解释。F12 的场景牵引、F11 的 OOD 边界、F10 的探针位置反转,都是现象层观察。它们能限制一些解释,但还不能直接说明 forward pass 里具体计算了什么。
所以我现在愿意保留的版本是:Pythia-6.9B base 的残差流里确实有一些方向,和 30 个 emotion label 部分相关;这些方向在几何上会压到约 5 个 valence/arousal 维度;在合适的 α 区间内,steering 也能产生可读的目标情绪相关变化。
但更强的说法还没到:严格线性表征、干净的 emotion concept、论文那种 sensory/action 分工,都还需要额外实验。
+ 数据 / 代码 F4 · F5
+ data / code
附录appendix
F1 完整 logit lens 表 — 30 emotion × top-5 tokens (L21)F1 full logit lens table — 30 emotions × top-5 tokens (L21)
原始 logit lens 输出(含 BPE 截断的子词 token,例如 tranqu 是 tranquil 的前缀),未做后处理。正文
§3 F1 引用 calm / desperate 的版本做过 polish 替换(如 tranqu→tranquil),此表是 raw output 供对照。
| Emotion | top-1 | top-2 | top-3 | top-4 | top-5 |
|---|---|---|---|---|---|
| angry | anger |
rage |
fury |
indign |
pissed |
| anxious | panic |
worse |
paranoid |
worst |
nerv |
| ashamed | ashamed |
shame |
embarrassed |
dishon |
excuses |
| bored | bored |
boring |
monoton |
dull |
tedious |
| brooding | mourning |
mour |
mourn |
numb |
fucked |
| calm | peace |
peaceful |
relaxing |
tranqu |
rhythm |
| confused | confusing |
unclear |
either |
confused |
Either |
| content | relaxing |
peace |
relaxed |
relaxation |
peaceful |
| curious | clues |
puzz |
mystery |
mysteries |
answers |
| desperate | panic |
desperation |
desperate |
numb |
helpless |
| disgusted | disgust |
disgusting |
disg |
vom |
contempt |
| enthusiastic | excited |
excitement |
enthusi |
eagerly |
exciting |
| excited | excitement |
excited |
eagerly |
exciting |
enthusi |
| frustrated | frustration |
frustrated |
pissed |
frustrating |
:( |
| furious | rage |
anger |
fury |
furious |
fucking |
| gloomy | depressing |
mourning |
mourn |
bleak |
loneliness |
| grateful | kindness |
gratitude |
unconditional |
healing |
healed |
| guilty | guilt |
selfish |
blame |
culp |
remorse |
| happy | 🙂 |
enthusi |
excited |
delight |
happily |
| hopeful | healed |
survived |
healing |
resilience |
restored |
| jealous | theirs |
jealousy |
jealous |
hers |
envy |
| lonely | loneliness |
lonely |
alone |
solitary |
strangers |
| loving | love |
love |
loving |
tenderness |
unconditional |
| nervous | panic |
nerv |
nerves |
trembling |
anxiety |
| nostalgic | younger |
grandchildren |
nost |
aging |
memory |
| panicked | panic |
panic |
adren |
nightmare |
paranoid |
| playful | !" |
hilarious |
enthusi |
hilar |
\" |
| proud | proudly |
rewarding |
dedication |
inspiring |
confident |
| sad | mourning |
mour |
sadness |
mourn |
anymore |
| surprised | realised |
astonished |
Wow |
recognised |
unexpectedly |
F4 — L14 是 Pythia 30-way classifier 最优层 (🔄 Reframed)F4 — L14 is Pythia 30-way classifier's best layer (🔄 Reframed)
在 32 层全扫 30-way classifier,L14(44% depth)= 34.6% 是最优。早期版本把这个结果和论文约 2/3 depth 的层选择直接对立起来,这个比较不合适:论文选中后层主要是因为它关心下游 sampled tokens 的 action representation;这里测的是 classification accuracy。重新表述后,F4 + F12 更适合读成:classifier 最优层不一定等于 steering 最优层。完整 layer scan 数字见附图。跨模型 depth fraction 比较也要克制:Pythia 是 32 层 base,Sonnet 层数未公开且是 chat model,架构和 training stage 都不同。
F5 — L14 PCA cluttered vs L21 clean 撤回F5 — L14 PCA cluttered vs L21 clean: retracted
最初的读图是:L14 PCA 二维图比较杂,L21 二维图更干净,于是我写过一个解释:L14 高维信息丰富但二维图丢信息,L21 则把结构压到了更低维。
后来回头看数值,L14 PCA top-2 var = 49.4%,L21 = 49.9%,几乎相同。L14 PC1 也是 valence(只是符号反),跟 L21 没有本质差别。所以这条不再作为发现保留;它更像是二维可视化读图过度造成的 artifact。
完整数据 / 代码data / code
- 数据:30 × 120 emotion stories(Claude 4.5 生成)+ 500 wikitext-103 中性段落
- 主要脚本:
phase1_emotion_vectors.py/phase2_validation.py/phase3_steering.py/f3_method_comparison.py/phase2_dialogue_test_L21.py等 - Repo:github.com/Fuchsia-L/emotion-probing-pythia(含全部脚本 + 30×120 emotion stories 数据集 + 5 张正文 figure)